

How To Clean Data As A Data Scientist
What is Data Cleaning? How to Procedure Information for Analytics and Automobile Learning Modeling?
Information Cleaning plays an important role in the field of Data Managements likewise as Analytics and Machine Learning. In this article, I will try to requite the intuitions nearly the importance of information cleaning and different data cleaning processes.
What is Information Cleaning?
Information Cleaning means the process of identifying the wrong, incomplete, inaccurate, irrelevant or missing part of the information and so modifying, replacing or deleting them co-ordinate to the necessity. Data cleaning is considered a foundational element of the basic information science.
Data is the most valuable thing for Analytics and Machine learning. In computing or Business organization data is needed everywhere. When it comes to the real world data, it is not improbable that information may contain incomplete, inconsistent or missing values. If the data is corrupted then it may hinder the process or provide inaccurate results. Allow's see some examples of the importance of information cleaning.
Suppose yous are a general director of a visitor. Your visitor collects data of different customers who buy products produced by your visitor. Now you want to know on which products people are interested most and co-ordinate to that you want to increase the product of that product. But if the information is corrupted or contains missing values and so you will be misguided to make the correct decision and you will be in trouble.
At the stop of all, Machine Learning is a data-driven AI. In machine learning, if the data is irrelevant or fault-prone then information technology leads to an incorrect model building.
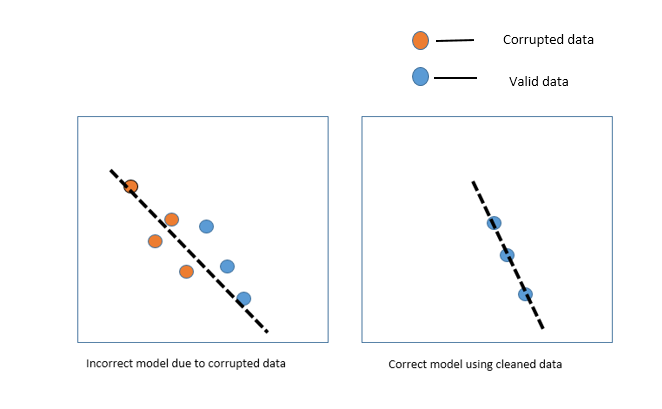
As much as y'all make your data clean, equally much as you tin can brand a better model. So, we need to process or clean the data before using information technology. Without the quality information,it would be foolish to expect anything good outcome.
Different Ways of Cleaning Information
Now let'due south have a closer look in the different ways of cleaning data.
Inconsistent column :
If your DataFrame (A Information frame is a two-dimensional data structure, i.e., information is aligned in a tabular fashion in rows and columns) contains columns that are irrelevant or you are never going to apply them then you can driblet them to requite more focus on the columns you will work on. Let's see an case of how to deal with such data set. Let'southward create an example of students data set using pandas DataFrame.
import numpy as np # linear algebra import pandas as pd # information processing, CSV file I/O data={'Name':['A','B','C','D','Eastward','F','G','H']
,'Top':[v.2,5.7,v.six,5.5,5.3,five.8,5.vi,5.5],
'Scroll':[55,99,15,80,1,12,47,104],
'Department':['CSE','EEE','BME','CSE','ME','ME','CE','CSE'],
'Accost':['polashi','banani','farmgate','mirpur','dhanmondi','ishwardi','khulna','uttara']} df=pd.DataFrame(information)
print(df)
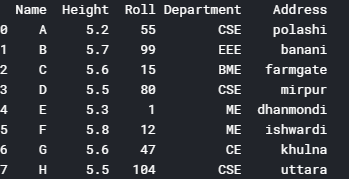
Here if we desire to remove the "Height" column, we can utilize python pandas.DataFrame.drop to drop specified labels from rows or columns.
DataFrame.drib(cocky, labels=None, axis=0, index=None, columns=None, level=None, inplace=Simulated, errors='heighten') Let us driblet the top column. For this you lot need to push the column name in the column keyword.
df=df.drop(columns='Height')
impress(df.head()) 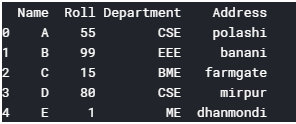
Missing data:
It is rare to have a real world dataset without having any missing values. When yous starting time to work with real globe data, you will find that most of the dataset contains missing values. Treatment missing values is very important because if you lot leave the missing values as it is, it may bear upon your analysis and machine learning models. Then, you need to exist certain that whether your dataset contains missing values or not. If you observe missing values in your dataset you must handle information technology. If y'all find any missing values in the dataset y'all can perform any of these three chore on information technology:
1. Leave as it is
two. Filling the missing values
3. Drop them
For filling the missing values nosotros tin can perform different methods. For example, Figure iv shows that airquality dataset has missing values.
airquality.head() # return elevation due north (v past default) rows of a information frame 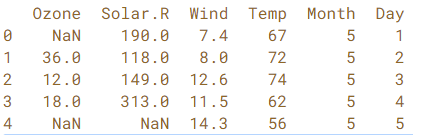
In effigy 4, NaN indicates that the dataset contains missing values in that position. After finding missing values in your dataset, You lot can employ pandas.DataFrame.fillna to fill the missing values.
DataFrame.fillna(self, value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs) Y'all can apply dissimilar statistical methods to fill the missing values according to your needs. For example, here in figure 5, we will use the statistical mean method to fill the missing values.
airquality['Ozone'] = airquality['Ozone'].fillna(airquality.Ozone.mean()) airquality.head()
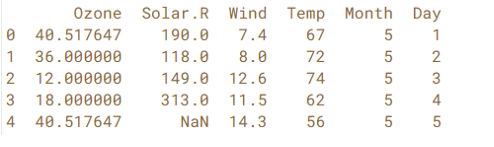
Yous can see that the missing values in "Ozone" column is filled with the mean value of that column.
You can also drib the rows or columns where missing values are found. we drib the rows containing missing values. Here You tin drop missing values with the help of pandas.DataFrame.dropna .
airquality = airquality.dropna() #drop the rows containing at least one missing value airquality.head()
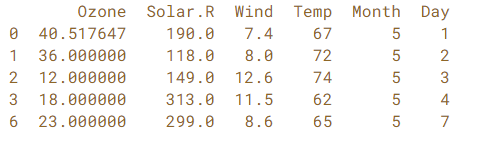
Hither, in effigy 6, you tin see that rows have missing values in column Solar.R is dropped.
airquality.isnull().sum(axis=0) 
Outliers:
If yous are new information Scientific discipline then the first question that will arise in your caput is "what does these outliers mean" ? Let's talk about the outliers outset and and so nosotros will talk nigh the detection of these outliers in the dataset and what will nosotros do after detecting the outliers.
According to wikipedia,
"In statistics, an outlier is a data point that differs significantly from other observations."
That means an outlier indicates a data betoken that is significantly different from the other data points in the data set. Outliers can be created due to the errors in the experiments or the variability in the measurements. Let's look an case to articulate the concept.
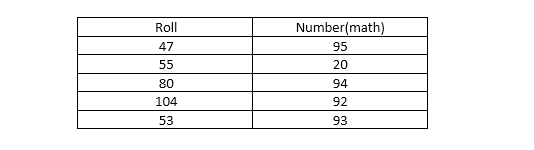
In Figure 4 all the values in math column are in range betwixt 90–95 except 20 which is significantly different from others. It can be an input fault in the dataset. So nosotros can call information technology a outliers. One matter should be added here — " Not all the outliers are bad data points. Some tin be errors but others are the valid values. "
And so, now the question is how can nosotros observe the outliers in the dataset.
For detecting the outliers we can use :
1. Box Plot
two. Scatter plot
3. Z-score etc.
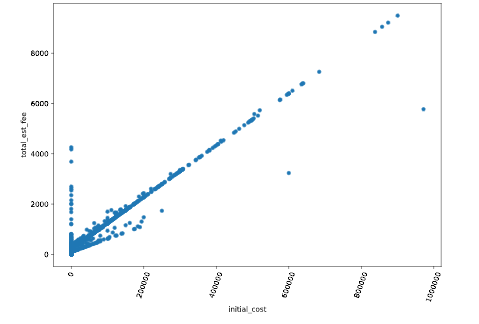
We will see the Scatter Plot method here. Allow'due south draw a scatter plot of a dataset.
dataset.plot(kind='scatter' , ten='initial_cost' , y='total_est_fee' , rot = 70)
plt.bear witness() 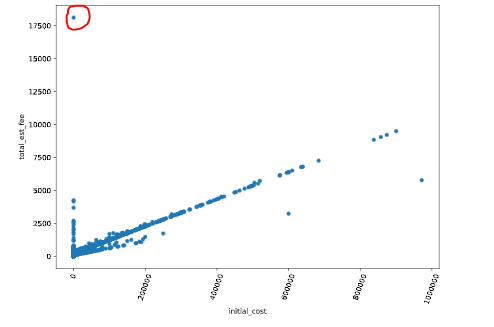
Here in Effigy 9 there is a outlier with cherry-red outline. After detecting this, we can remove this from the dataset.
df_removed_outliers = dataset[dataset.total_est_fee<17500] df_removed_outliers.plot(kind='scatter', x='initial_cost' , y='total_est_fee' , rot = 70) plt.prove()
Duplicate rows:
Datasets may contain duplicate entries. It is one of the most easiest task to delete duplicate rows. To delete the duplicate rows you tin use —
dataset_name.drop_duplicates(). Figure 12 shows a sample of a dataset having indistinguishable rows.
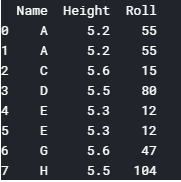
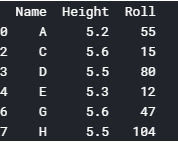
dataset=dataset.drop_duplicates()#this will remove the duplicate rows. impress(dataset)
Tidy data set:
Tidy dataset means each columns represent separate variables and each rows correspond individual observations. But in untidy data each columns correspond values but not the variables. Tidy data is useful to fix mutual information problem.You tin turn the untidy data to tidy data by using pandas.melt .
import pandas as pd
pd.melt(frame=df,id_vars='name',value_vars=['treatment a','treatment b']) 
You can also run across pandas.DataFrame.pivot for un-melting the tidy data.
Converting information types:
In DataFrame data can be of many types. As example :
1. Chiselled information
2. Object data
3. Numeric data
4. Boolean data
Some columns data type can be changed due to some reason or have inconsistent data blazon. Yous tin can convert from one information blazon to another past using pandas.DataFrame.astype .
DataFrame.astype(cocky, dtype, copy=True, errors='raise', **kwargs) String manipulation:
1 of the most of import and interesting part of data cleaning is cord manipulation. In the real world most of the data are unstructured information. String manipulation means the process of changing, parsing, matching or analyzing strings. For string manipulation, yous should have some cognition about regular expressions. Sometimes you demand to excerpt some value from a large sentence. Here string manipulation gives the states a strong benefit. Permit say,
"This umbrella costs $12 and he took this money from his mother."
If you want to verbal the "$12" information from the sentence then you have to build a regular expression for matching that pattern.Later on that yous can use the python libraries.At that place are many built in and external libraries in python for cord manipulation.
import re blueprint = re.compile('|\$|d*') result = pattern.match("$12312312") impress(bool(result))
This will give y'all an output showing "True".
Information Concatenation:
In this modern era of information science the volume of data is increasing day past solar day. Due to the large number of book of information data may stored in separated files. If you work with multiple files then yous can concatenate them for simplicity. Y'all can use the post-obit python library for concatenate.
pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=Imitation, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=True) Let'south see an example how to concatenate ii dataset. Figure 14 shows an case of two dissimilar datasets loaded from ii dissimilar files. We volition concatenate them using pandas.concat .
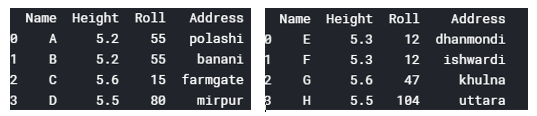
concatenated_data=pd.concat([dataset1,dataset2])
print(concatenated_data) 
Conclusion:
Information Cleaning is very import for making your analytics and machine learning models error-gratuitous. A small error in the dataset tin crusade you a lot of problem. All your efforts tin can be wasted. So, ever try to brand your data clean.
References:
ane. Dataframe
2. DataCamp-Cleaning information in python
3. Working with missing information
iv. How to remove outliers in Data with Pandas
5. Ways to Detect and Remove the Outliers
six. Outlier removal clustring
7. 3 ways to remove outliers from your data
viii. pandas.DataFrame.astype
9. pandas.concat
10. pandas.DataFrame.cook
eleven. Tidy data
And Finally, Thank Yous for Reading.

Source: https://towardsdatascience.com/what-is-data-cleaning-how-to-process-data-for-analytics-and-machine-learning-modeling-c2afcf4fbf45
Posted by: comerolvery.blogspot.com
0 Response to "How To Clean Data As A Data Scientist"
Post a Comment